目前我們總共用了三種optimizer:SGD、RMSprop和Adam,關於optimizer的介紹可以參考這篇和這篇,其中SGD(stochastic gradient decent)是最基礎入門款,而Adam(Adaptive Moment Estimation)是目前集各家優點,最被推薦使用的,今天我們回來看基礎版的SGD一個很常被探討的參數:學習率(learning rate)。
下圖是借用這篇中很常見來闡述learning rate,白話的來說就像我們再往最低點的loss前進時,如果一步太小會走很慢,一步太大又怕走過頭。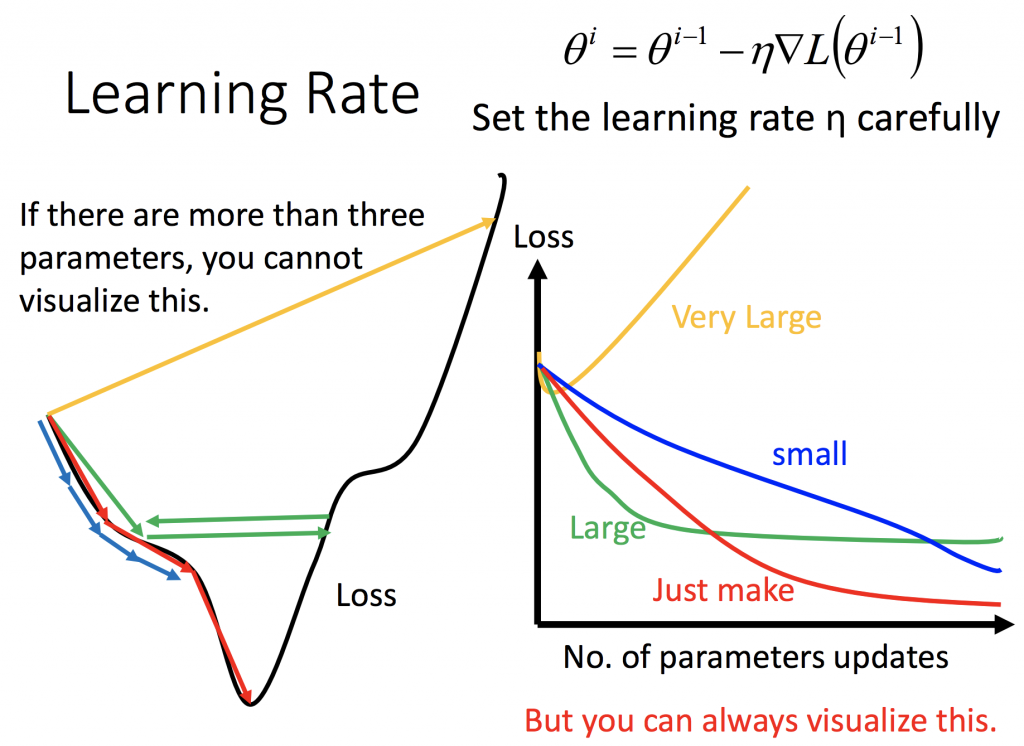
所以簡單的策略就是距離遠的時候走大步一點,反之距離近的時候走小步,其中距離可以換成坡度或是次數。這就是RMSprop、AdaGrad和Adam所具有的概念。但我們來看在用SGD時,怎麼實現這個方法,我們用簡單點的,讓它是epoch的參數:
# Set the learning rate scheduler
lr_schedule = tf.keras.callbacks.LearningRateScheduler(
lambda epoch: 1e-8 * 10**(epoch / 20))
# Initialize the optimizer
optimizer = tf.keras.optimizers.SGD(momentum=0.9)
# Set the training parameters
model.compile(loss="mse", optimizer=optimizer)
這樣就可以了。而此時有人可能會想到如果眼前的這個最低點不是真正的最低點,而只是局部所見呢?那可以參考momentum的理論。但我想我還是都會先用Adam作為標竿,方便用簡單。


 iThome鐵人賽
iThome鐵人賽